📚 计算
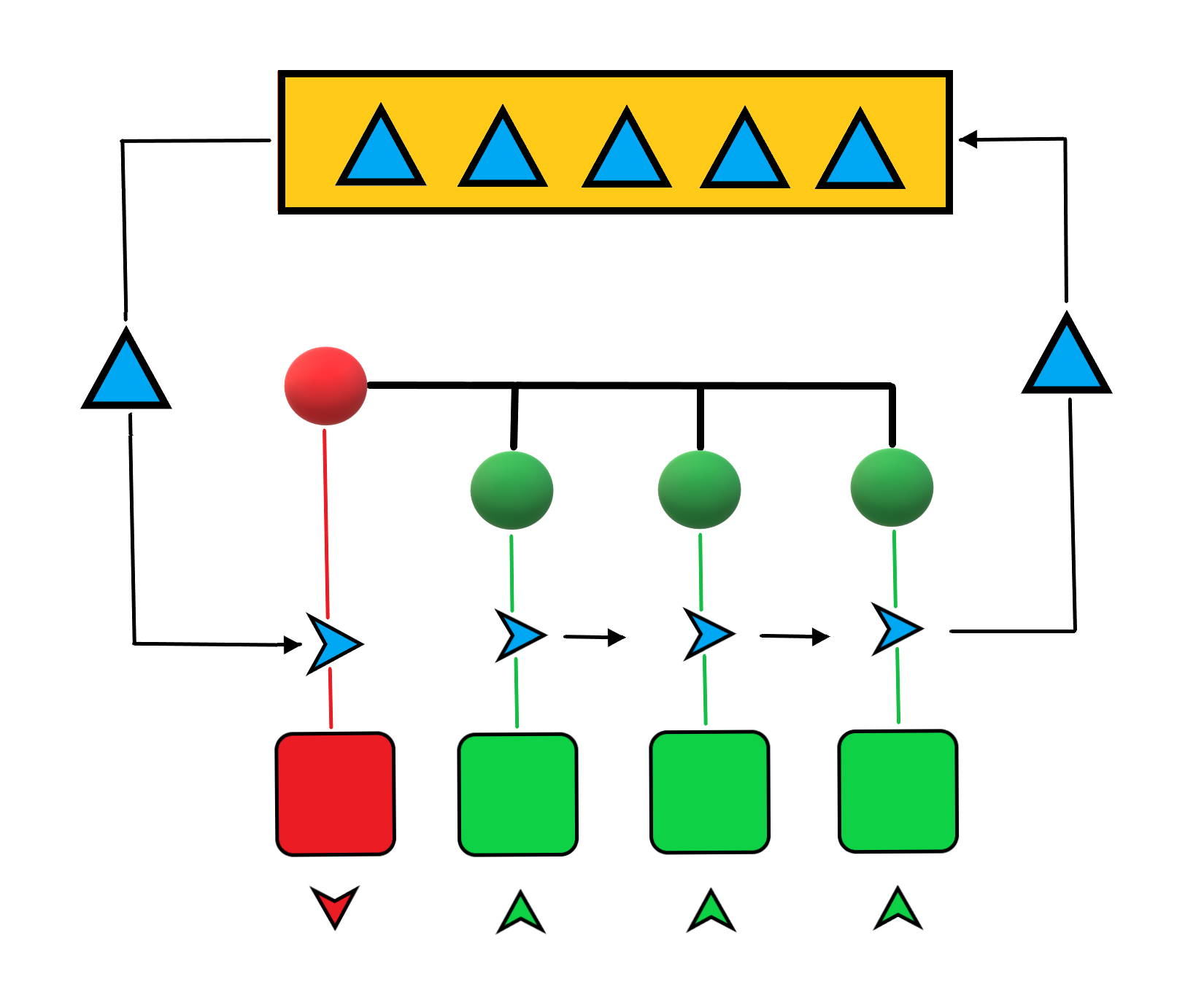 Thinker™ 的设计基于一个假设:运行时计算结构复杂且异构。
类似GPU的设备似乎无法满足需求,因为它的目标是让数千个运算核心同时计算相同的内核软件。
相反,Thinker 中的一个项目可以包含数千个不同的函数,每个函数都在其本地网络区域进行计算。
这种设计很可能在FPGA硬件加速下表现良好。
Thinker™ 的设计基于一个假设:运行时计算结构复杂且异构。
类似GPU的设备似乎无法满足需求,因为它的目标是让数千个运算核心同时计算相同的内核软件。
相反,Thinker 中的一个项目可以包含数千个不同的函数,每个函数都在其本地网络区域进行计算。
这种设计很可能在FPGA硬件加速下表现良好。
尽管如此,该程序承诺以几乎并行的方式处理数据。
严格来说,在当代CPU硬件上不可能实现完全并行计算。
软件代码按照其自身的调度,经过优化方案和多级缓存,到达可用的计算核心。
计算结果会沿原路返回主内存。仔细研究后,会发现这是一个非常复杂的过程。
由于 Thinker 是一个 Java¹ 应用程序,其并行计算基于该语言的
ExecutorService 技术。
它允许根据需要使用尽可能多的虚拟处理器。
可用数学硬件核心与活动线程数的比率决定了运行时的并行度。
一些进程应该并行运行,而其他进程则停留在队列中等待可用的硬件。
 Thinker 运行时设计始终提供默认的
Thinker 运行时设计始终提供默认的 ExecutorService 服务。
此外,模型可以根据需要包含任意数量的独立服务(在模型中称为“处理器”),用于设计层次结构的任何部分。
主处理器和补充处理器均具有服务执行控件。
指定的 Java 服务可以运行(重启)计算、暂停和完全停止。
所有补充处理器均独立管理。
主处理器的控件管理整套处理器。
项目的控件也在其自身内容范围内管理。
每个 Thinker 处理器的运行方式²都让人联想到餐厅服务员的服务。
它从专用计算点接收“订单”,将其放入队列,并按完成顺序返回结果。
在使用默认处理器类时,
可以修改此标准策略。
订单在队列中可能会自然出现重复。
处理器设置允许将相同的订单合并为一个,直到满足另一个订单。
或者,可以从整个队列中删除所有重复的订单。
当模型逻辑可以接受此类策略时,这些偏差可以显著提高性能。
另一个特性允许将实际处理延迟一段时间,直到发生特定事件:超时或队列累积了足够的订单。
它可以补偿函数参数值到达不同步的情况,这种情况在实践中经常发生。
 Thinker 的桌面版本构建了所有元素均可观察的运行时模型。
当某个元素获得新值或更改其状态时,该元素的所有监听器都会立即收到此更新。
“分析器”选项卡中的时间线框架和“属性”弹出窗口就是此类监听器的示例。
对于特殊的应用场景,Thinker 可以生成不可观察的运行时模型,以提高整体处理性能。
无论如何,该模型仍然可以通过附加到
Thinker 的桌面版本构建了所有元素均可观察的运行时模型。
当某个元素获得新值或更改其状态时,该元素的所有监听器都会立即收到此更新。
“分析器”选项卡中的时间线框架和“属性”弹出窗口就是此类监听器的示例。
对于特殊的应用场景,Thinker 可以生成不可观察的运行时模型,以提高整体处理性能。
无论如何,该模型仍然可以通过附加到 field 元素的自定义 Java 类与外部世界交互。
笔记:
- 软件版本 2.X 是使用 Java 版本 15 SDK 构建的,这主要是从正在使用的 Neo4j 数据库版本继承的限制。
- EU 专利申请中。
| 章节
买
教程
|